
Implementing Zero Trust Architecture on Kubernetes with GitOps, Istio, and ArgoCD
Zero Trust is not a product, it’s an operating model
Most teams treat “security” as something that happens at the perimeter: a login page, maybe an API gateway, and then “the internal network” where things are assumed safe.
Kubernetes breaks that model by design.
Workloads are ephemeral, networks are flat by default, service-to-service traffic dominates, and delivery pipelines ship changes continuously. If you keep a perimeter-only mindset, your cluster ends up like a modern city with one guarded gate and thousands of unguarded side streets.
Zero Trust Architecture (ZTA) flips the assumption:
- No implicit trust based on network location
- Every request is verified using identity and context
- Least privilege is enforced everywhere, not only at the edge
- Assume breach and design for containment
- Continuous verification through telemetry
This article explains how the following architecture implements those principles end-to-end.
Reference architecture overview
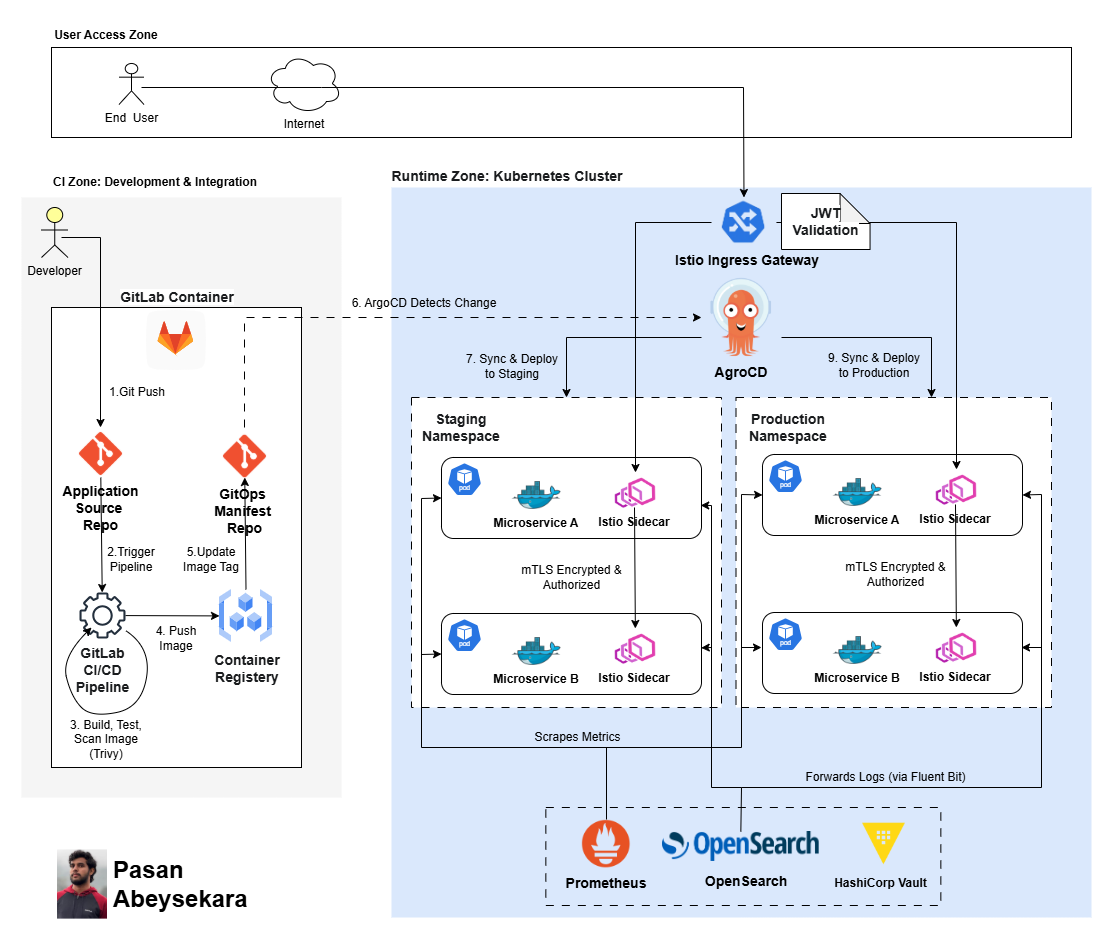
- End-to-end Zero Trust flow: Developer → CI (build/test/scan) → Registry → GitOps → ArgoCD → Staging → Production, with JWT at ingress and mTLS + policy enforcement inside the mesh.
The architecture is intentionally split into three zones:
1) User Access Zone
End users connect over the Internet, but they do not “reach the cluster.” They reach a single controlled entry point: the Istio Ingress Gateway, where requests are verified before being routed.
2) CI Zone: Development & Integration
This zone is where supply chain trust is established. A developer pushes code, CI builds and validates artifacts, security scanning happens, and the “what runs in production” decision becomes a Git change, not a manual cluster action.
3) Runtime Zone: Kubernetes Cluster
The cluster contains two clear environments Staging and Production each running microservices inside an Istio mesh with sidecars. Internal traffic is encrypted and policy-controlled. Observability and secrets management operate as first-class parts of the security model.
The core Zero Trust mapping
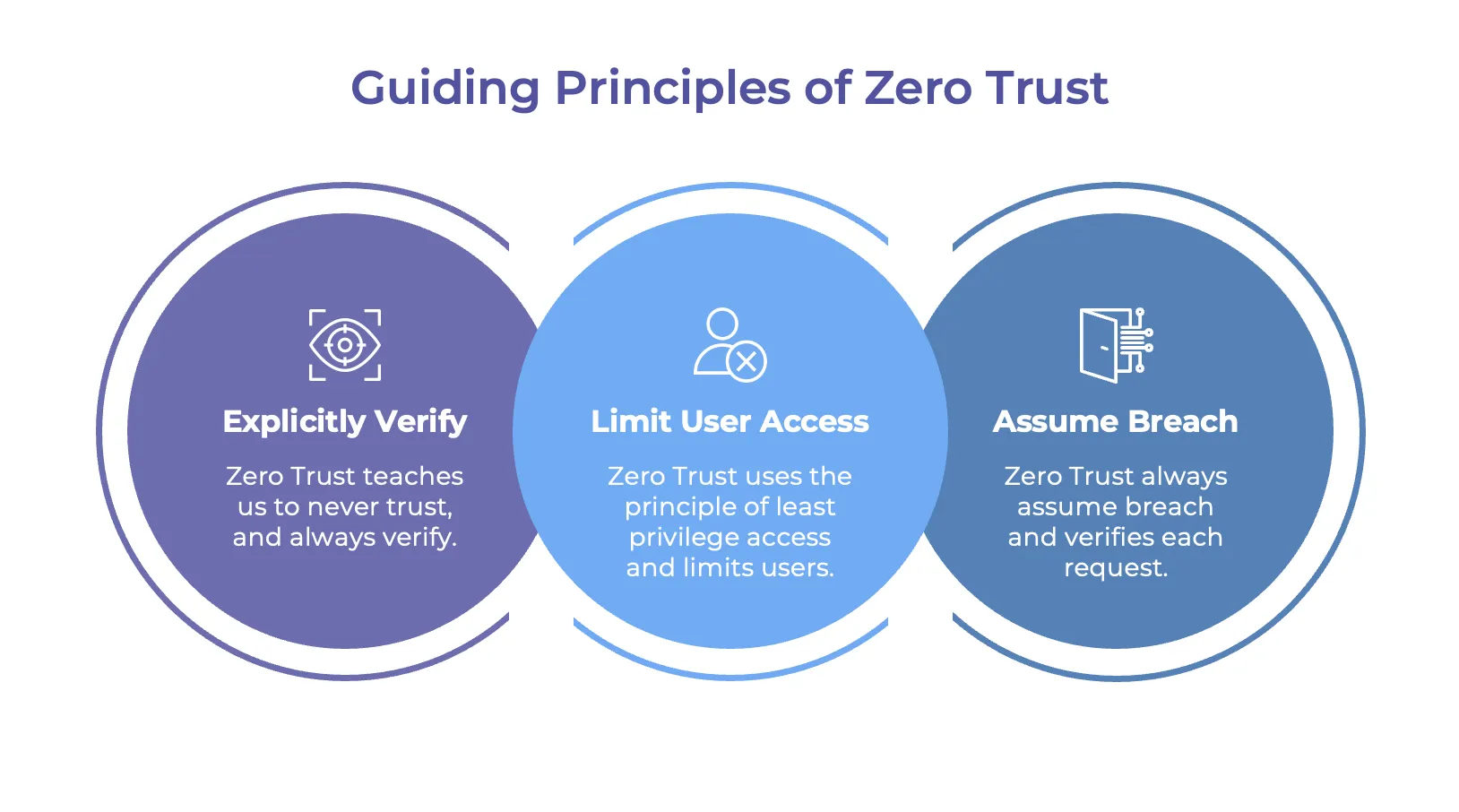
- Zero Trust principles applied to platforms: verify explicitly, enforce least privilege, assume breach, and continuously verify.
A useful way to evaluate any Zero Trust design is to ask four questions:
- Where is identity verified?
- How is least privilege enforced?
- How do you contain blast radius when something goes wrong?
- How do you continuously verify and detect violations?
This reference architecture answers each one explicitly.
Supply chain as a Zero Trust boundary (CI Zone)
The first major shift in modern Zero Trust is recognizing that “trust” begins before runtime. If the delivery pipeline is compromised, everything downstream inherits that compromise.
In this architecture, the CI Zone enforces three security ideas:
‣ Artifact integrity: what runs must be produced through automation
A developer performs a git push to the Application Source Repo. That triggers the CI pipeline. The pipeline becomes the only reliable mechanism for producing deployable artifacts.
The key outcome: production is not deployed from laptops.
‣ Vulnerability reduction: scanning becomes a promotion gate
The pipeline includes a security scan stage (shown as Trivy in the diagram). The point is not “Trivy specifically.” The point is that security becomes a gate, not a report.
This aligns with Zero Trust’s “assume breach” principle: assume known vulnerabilities will be exploited if they are shipped.
‣ Separation of duties: app repo vs GitOps manifests repo
One of the most underrated ZTA moves here is the split:
- Application code lives in the Application Source Repo
- Deployment intent lives in the GitOps Manifests Repo
That means even if an attacker alters application code, they still don’t automatically control what’s deployed. Conversely, changes to production configuration become reviewable, auditable Git history.
GitOps turns deployments into a controlled trust workflow
GitOps is not just “cool DevOps.” In Zero Trust, GitOps is a security control.
The diagram shows a clear pattern:
- CI publishes an image to the registry
- CI updates the GitOps repo with a new image tag
- ArgoCD notices the GitOps change and reconciles the cluster
This matters because the cluster is no longer “a place where people make changes.” It’s a system that continuously converges to approved state.
When Zero Trust says “never trust,” it includes: never trust ad-hoc runtime drift.
ArgoCD as the runtime policy enforcer for desired state
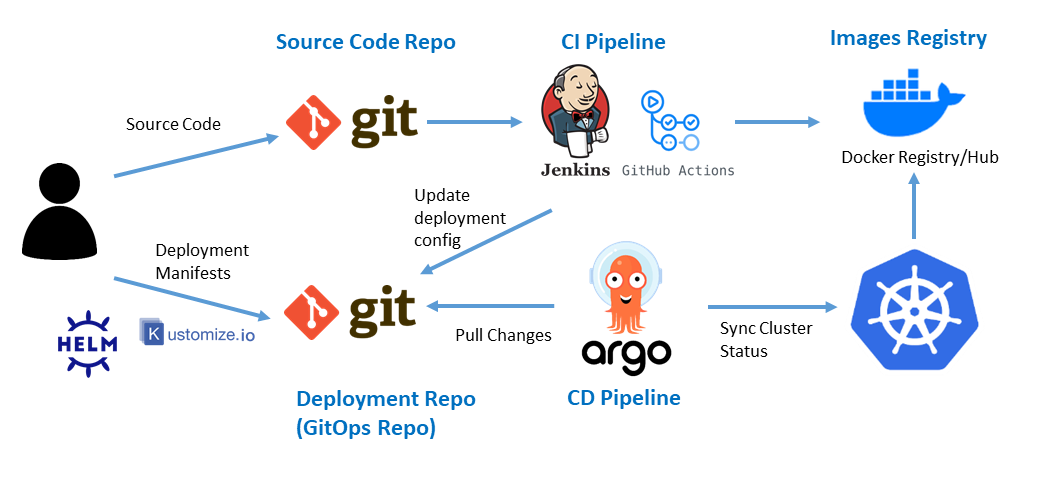
- GitOps promotion model: CI publishes an immutable artifact, GitOps records desired state, and ArgoCD continuously reconciles staging first, then production via controlled promotion.
ArgoCD is depicted as the central runtime orchestrator. It performs a security-critical function:
- Detect change
- Sync & deploy to staging
- Sync & deploy to production
That staging-first flow is not cosmetic. It builds two Zero Trust advantages:
Controlled promotion reduces blast radius
Staging acts as a containment layer. If something is wrong (bug, misconfig, vulnerable build), it is more likely to be detected before production.
Production changes become intentional events
A mature GitOps model treats production deployment as a promotion decision something that happens because a particular state was approved, not because “the pipeline ran.”
That makes production deployments traceable and reviewable, which directly supports audit and incident response.
Identity at the edge: JWT verification at Istio Ingress Gateway
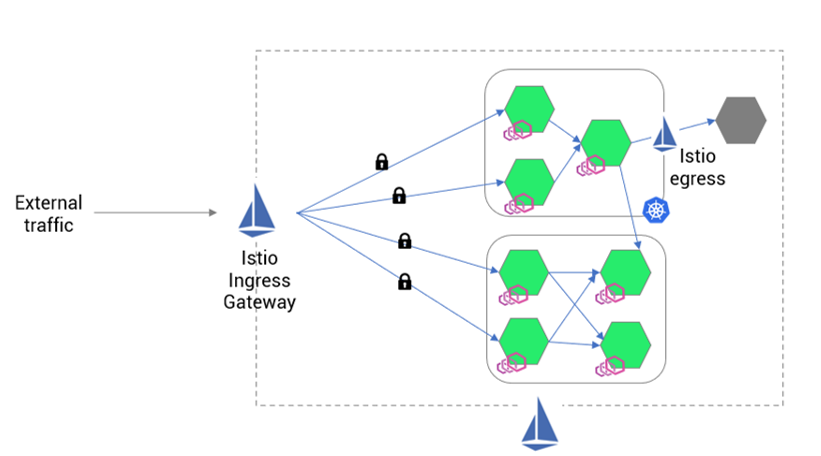
- dentity-aware ingress: every external request is verified at the gateway (JWT validation) before it can reach internal services.
In the User Access Zone, the only path into the cluster is through Istio Ingress Gateway, and the diagram explicitly labels JWT Validation.
This is the Zero Trust “verify explicitly” principle in action.
JWT validation here is not just authentication. It enables:
- Request identity: who is making this call?
- Claims-based context: roles, scopes, tenant, device posture (if included upstream)
- Consistent enforcement: every inbound request hits the same verification layer
A major security win of doing this at the gateway is that microservices are not forced to implement inconsistent authentication logic. You centralize verification and then enforce authorization downstream.
The most important part: Zero Trust inside the cluster (east-west traffic)
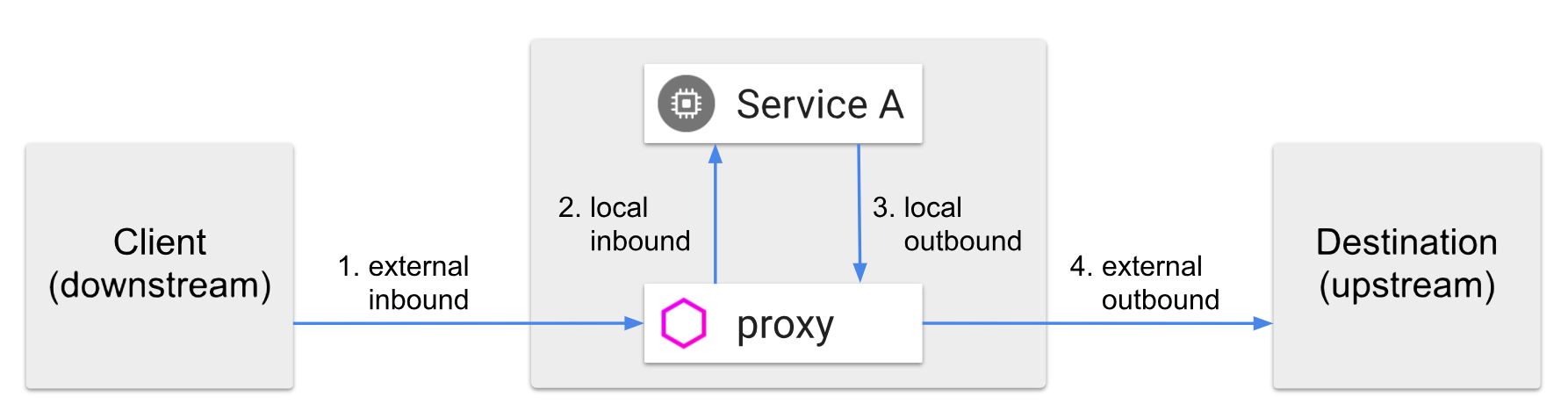
- Zero Trust east–west: service-to-service traffic is encrypted with mTLS and authenticated via workload identity, removing “trusted internal network” assumptions
Most real-world breaches are not about breaking the front door. They’re about what happens after something gets in.
That’s why the architecture emphasizes two things inside both namespaces:
- Istio Sidecar per service
- mTLS Encrypted & Authorized
This is where Zero Trust becomes real.
mTLS: encryption + workload identity
mTLS does two jobs at once:
- Encrypt traffic so internal calls can’t be sniffed or trivially intercepted
- Authenticate workloads so services can verify who is calling them
This eliminates the “internal network trust” anti-pattern. Services don’t trust requests because they came from a cluster IP; they trust them because they come with verified workload identity.
Authorization: least privilege for service-to-service communication
Encryption alone is not enough. You also need permissioning. This architecture assumes policy-based authorization governs which services can call which endpoints.
That supports least privilege in a very concrete form:
- A service should only accept calls from explicitly allowed identities
- A service should only expose the minimal routes needed
- Cross-namespace calls should be treated as high-trust boundaries
This is how you stop “one compromised pod” from becoming “full cluster compromise.”
Environment isolation: staging vs production is a security boundary
The diagram shows two namespaces that look similar by design: Staging and Production.
That similarity is important: you want production-like controls in staging so that tests are meaningful. But the separation is equally important because it enables:
Blast radius containment
A staging incident should not automatically threaten production. In practice, that means:
- separate namespaces
- separate policies
- separate secrets access
- separate deployment promotions
Reduced privilege pathways
A developer or automated system may be allowed to update staging continuously, but production should be protected through stricter gates. This aligns with “least privilege” applied to operations and change management.
Secrets governance: Vault makes identity matter for credentials
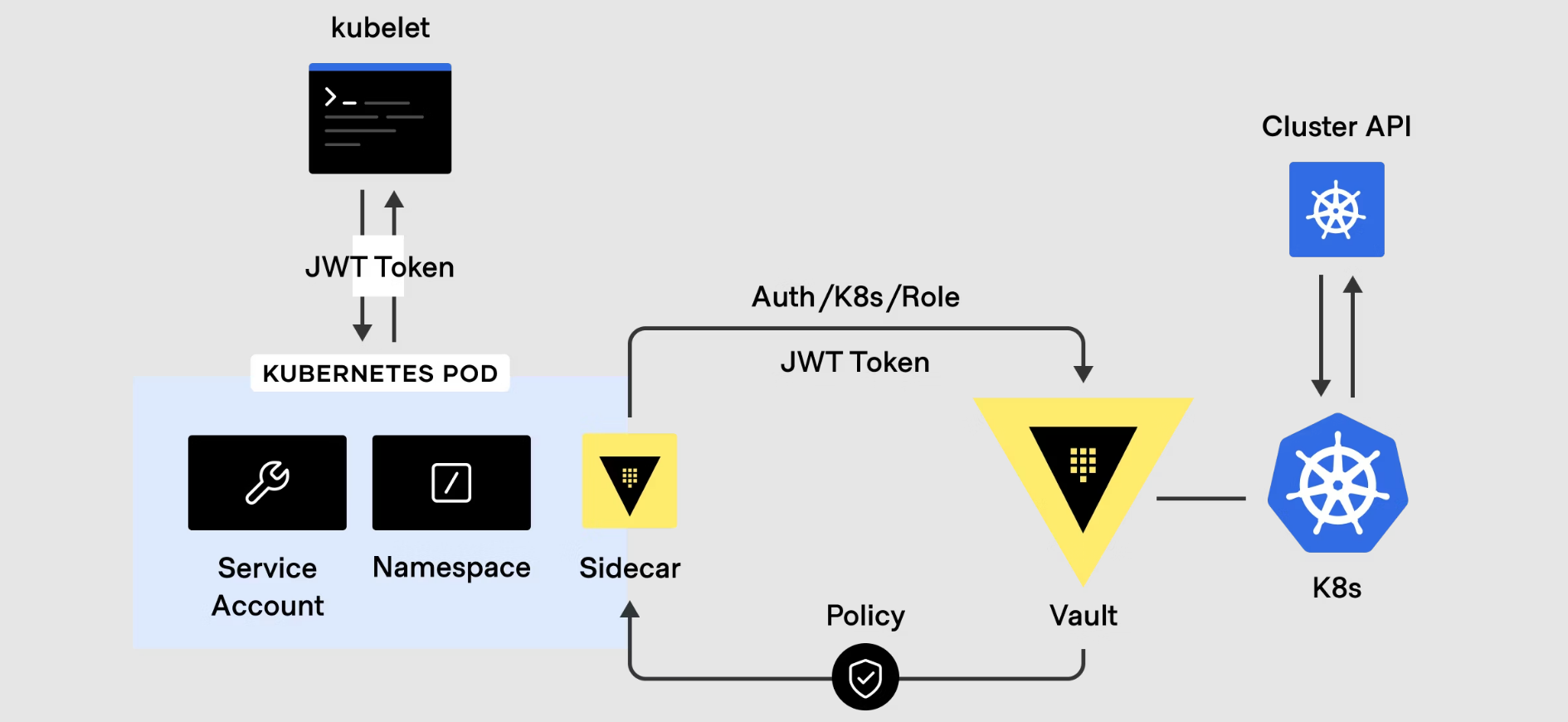
- Secrets tied to identity: workloads authenticate to Vault using their Kubernetes identity and receive only the secrets allowed by policy (least privilege, reduced blast radius)
Zero Trust is impossible if every service shares long-lived secrets.
The inclusion of HashiCorp Vault in the architecture is a statement: credentials must be governed as tightly as traffic.
Vault typically enables three Zero Trust outcomes:
1. Secrets tied to identity
Workloads authenticate to Vault using Kubernetes identity, which means secrets can be granted based on who the workload is, not where it runs.
2. Least privilege for sensitive data
Microservice A should not be able to read Microservice B’s secrets. Vault policies provide a clean enforcement layer for that separation.
3. Reduced credential lifetime (where possible)
Zero Trust favors short-lived credentials because even if something leaks, the window of exploitation is smaller.
Continuous verification: Prometheus + centralized logging (OpenSearch)
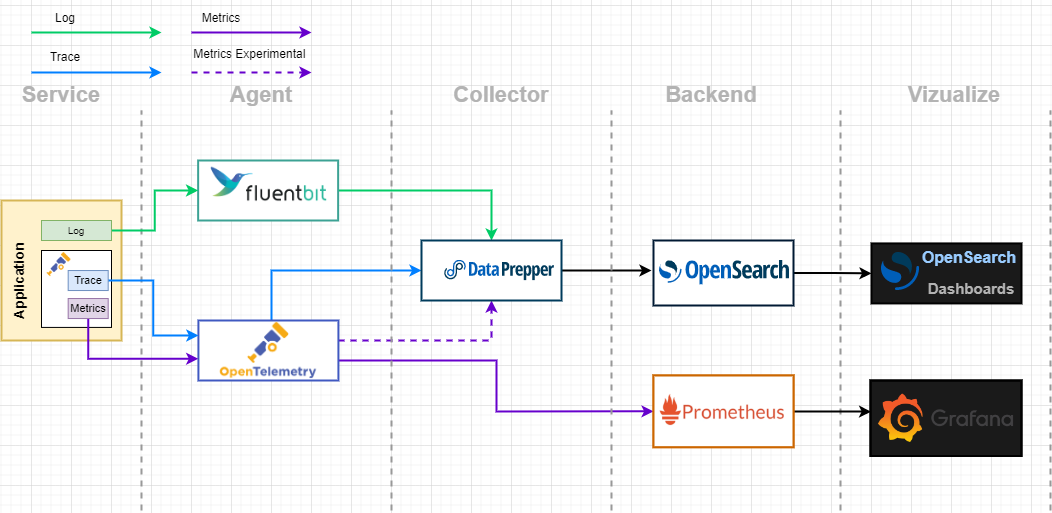
- Continuous verification: metrics (Prometheus) and centralized logs (Fluent Bit→OpenSearch) provide evidence of JWT failures, authorization denials, anomalies, and drift.
Zero Trust assumes two uncomfortable truths:
- Controls will fail sometimes
- Attackers will eventually get partial access somewhere
So the system must continuously verify and provide evidence.
In this architecture:
- Prometheus scrapes metrics for services and mesh behavior
- Logs are forwarded via Fluent Bit into OpenSearch for analysis and retention
This isn’t “monitoring as an afterthought.” It’s part of your security posture.
What continuous verification looks like in practice
A ZTA-oriented observability setup prioritizes signals like:
- JWT verification failures at the gateway
- Spikes in 401/403 responses for protected routes
- Service-to-service authorization denials (unexpected callers)
- Unusual east-west traffic patterns (new communication edges)
- Deployment drift and repeated reconciliation events
These signals turn Zero Trust from “policy statements” into operational reality.
How the full request path is verified end-to-end
Putting it together, a single request follows a security chain:
-
Developer → CI A change becomes a build artifact through controlled automation and scanning.
-
CI → GitOps repo Deployment intent is recorded as Git state.
-
ArgoCD → Staging → Production Cluster converges to approved state; production is promoted intentionally.
-
User → Istio Gateway (JWT) The request is authenticated and verified before entering internal routing.
-
Gateway → Service mesh (mTLS + policy) Internal traffic is encrypted; workloads identify each other; calls are authorized.
-
Vault provides secrets per workload identity Services receive only the credentials they are entitled to use.
-
Metrics + logs continuously validate behavior Failures and anomalies become searchable, alertable evidence.
That’s a complete Zero Trust story: secure delivery + verified ingress + controlled east-west communication + governed secrets + continuous verification.
Common failure modes this architecture avoids
Even strong teams get Zero Trust wrong in predictable ways. This architecture prevents several common traps:
‣ “We validate JWT at the edge, so we’re safe”
Edge verification is necessary, but most breaches become dangerous through lateral movement. The mesh controls are what stop that.
‣ “We enabled mTLS, so internal traffic is secure”
mTLS without authorization can still allow “any service can call any service.” Encryption is not least privilege.
‣ “Staging is just like production”
Staging should resemble production, but it must not share the same privilege and secrets boundary. Similar controls, different entitlements.
‣ “We use GitOps but people still hotfix production”
Once manual cluster mutation is normalized, audit and containment collapse. GitOps must be treated as the authoritative pathway.
‣ “We have logs and metrics but we don’t look at denials”
Zero Trust requires you to treat denials and failed verifications as first-class signals.
This reference architecture implements Zero Trust as a complete operating model not a checklist item.
- GitLab CI + scanning reduces supply chain risk and makes artifacts traceable
- GitOps turns deployment intent into versioned, reviewable state
- ArgoCD enforces desired state and enables controlled staging→production promotion
- Istio Gateway with JWT provides identity-aware ingress verification
- Istio sidecars with mTLS + authorization prevent lateral movement and enforce least privilege
- Vault governs secrets through workload identity
- Prometheus + Fluent Bit → OpenSearch provide continuous verification and forensic evidence
If you implement these pieces together, you end up with something rare in Kubernetes security: a system where trust is not assumed anywhere, and every action deployments, requests, service calls, secret access has a verification path and an audit trail.